Die Bedeutung von «Algorithmen» in unserer Gesellschaft wächst rasant. Unter Algorithmen verstehe ich aber nicht nur Computercodes, sondern soziotechnische Systeme und institutionelle Prozesse, in denen mehr oder weniger lange Abschnitte der Entscheidungsketten automatisiert sind. Die Erweiterung der Einsatzgebiete von algorithmischen Systemen ist kein Zufall und auch kein Prozess, den man «aufhalten» kann oder sollte. Vielmehr ist es notwendig, eine differenzierte Kritik zu entwickeln, damit wir uns darüber verständigen können, welche Algorithmen wir brauchen und welche wir nicht wollen. Dies ist ein Vorschlag, wie eine solche Kritik aussehen könnte.
Beginnen wir mit drei Annahmen. Erstens: Wir brauchen Algorithmen als Teil einer Infrastruktur, die es erlaubt, soziale Komplexität und Dynamik so zu gestalten, dass diese unseren realen Herausforderungen gerecht werden. Zweitens: Viele Algorithmen sind handwerklich schlecht gemacht, vor allem jene, die soziales Alltagshandeln formen, also das tun, was Soziologen «soziales Sortieren» (David Lyon) oder «automatische Diskriminierung» (Oscar H. Gandy) nennen. Drittens: Diese handwerklichen Defizite sind nur ein Teil des Problems. Der andere Teil ergibt sich aus Problemen der politischen Programmatik, die vielen Algorithmen zugrunde liegt. Sie machen deutlich, dass es keine autonome Technologie gibt, auch wenn sie als «intelligent» oder «selbstlernend» bezeichnet wird. Gerade angewandte Technologien sind immer Teil von unternehmerischen oder administrativen Strategien, deren Reichweite und Effektivität sie verbessern sollen.
Wir brauchen Algorithmen
Dass algorithmische Systeme an Bedeutung gewinnen, hat mehrere Gründe. Die Menge und die Qualität des Dateninputs sind in den letzten Jahren enorm gestiegen und werden aller Voraussicht nach in den nächsten Jahren weiter steigen. Immer mehr Tätigkeiten und Zustände – online wie offline – hinterlassen immer detailliertere Datenspuren. Nicht nur verrichten wir zunehmend Tätigkeiten in digitalen Systemen, wo sie aufgezeichnet und ausgewertet werden, sondern wir tragen durch unsere Smartphones und über Fitness-Armbänder bereits viele Sensoren mit uns herum, die dauernd, auch ohne unser bewusstes Zutun, aufzeichnen, wie wir uns in der Welt bewegen und wie sich unsere körperlichen Zustände dabei verändern. Mit smart homes und smart cities werden immer mehr Sensoren in Innen- wie Außenräumen verbaut, die kontinuierlich aufzeichnen und weiterleiten, was in ihren jeweiligen Wahrnehmungsbereich fällt. Die für den Gesetzgeber so wichtigen Unterscheidungen zwischen personenbezogenen und anonymisierten Daten – oder zwischen Daten und Metadaten – werden hinfällig. Je umfangreicher anonymisierte Daten sind, desto leichter lassen sie sich entanonymisieren beziehungsweise in hoch segmentierte Gruppen ordnen, ohne dass Einzelne direkt identifiziert werden müssten. Metadaten sind oft aussagekräftiger als die Inhalte, die sie beschreiben, denn sie fallen standardisiert an und lassen sich deshalb viel effizienter auswerten.
Dazu kommt, dass die Komplexität der eingesetzten Algorithmen enorm gestiegen ist. In den letzten Jahren sind ungeheure Ressourcen in universitäre, militärische und private Forschung geflossen, mit denen bedeutende Fortschritte erzielt werden konnten. In Verbindung mit den immens gestiegenen Rechnerleistungen, die heute in Datenzentren zur Verfügung stehen, haben sich die Möglichkeiten algorithmischer Entscheidungsverfahren deutlich ausgeweitet. Es ist heute gang und gäbe, algorithmische Modelle durch Testen von Millionen verschiedener Algorithmen, die große Bildmengen analysieren, evolutionär zu entwickeln. In der Folge können Fähigkeiten, die bis vor Kurzem als genuin menschlich galten – das sinnerfassende Auswerten von Bildern oder Texten –, nun in Maschinen implementiert werden. Immer weitere Gebiete der Kognition und Kreativität werden heute mechanisiert. Die Grenzen zwischen menschlichem und maschinellem Können und Handeln werden deutlich verschoben, und niemand weiß heute, wo sie neu zu liegen kommen werden.
Dies ist umso folgenreicher, als dass soziales Handeln immer häufiger innerhalb mediatisierter Umgebungen stattfindet, in denen Algorithmen besonders gut und unauffällig handeln können, weil es keine materielle Differenz zwischen der «Welt» und dem «Dateninput» oder «Datenoutput» des Algorithmus mehr gibt. Online ist alles Code, alles Daten, alles generiert.
Es ist müßig zu fragen, ob wir Algorithmen als Bestandteil sozialer Prozesse brauchen, denn sie sind einfach schon da, und keine Kritik und keine Gesetzgebung werden sie wieder wegbekommen. Das wäre in dieser Pauschalität auch nicht wünschenswert. Denn wir brauchen durch neue technische Verfahren erweiterte individuelle und soziale Kognition, um uns in extrem datenreichen Umgebungen bewegen zu können, ohne an den Datenmengen zu erblinden. Ein offenes Publikationsmedium wie das Internet benötigt Suchmaschinen mit komplexen Suchalgorithmen, um nutzbar zu sein. Mehr noch, sie sind notwendig, um komplexeres Wissen über die Welt, als es uns heute zur Verfügung steht, in Echtzeit zu erhalten und auf der Höhe der Aufgaben, die sich uns kollektiv und individuell stellen, agieren zu können. Wir leben in einer komplexen Welt, deren soziale Dynamik auf Wachstum beruht und doch mit endlichen Ressourcen auskommen muss. Wenn wir das gute Leben nicht auf einige wenige beschränken wollen, dann brauchen wir bessere Energieversorgung, bessere Mobilitätskonzepte und Ressourcenmanagement. Das kann nur auf Basis «smarter» Infrastrukturen gelingen. Wenn wir etwa die Energieversorgung auf dezentrale, nachhaltige Energiegewinnung umstellen wollen, dann brauchen wir dazu intelligente, selbst steuernde Netze, die komplexe Fluktuationen von Herstellung und Verbrauch bewältigen können.
Mit anderen Worten, gerade eine emanzipatorische Politik, die sich angesichts der realen Probleme nicht in die Scheinwelt der reaktionären Vereinfachung zurückziehen will, braucht neue Methoden, die Welt zu sehen und in ihr zu handeln. Und Algorithmen werden ein Teil dieser neuen Methoden sein. Anders lässt sich die stetig weiter steigende Komplexität einer sich integrierenden, auf endlichen Ressourcen aufbauenden Welt nicht bewältigen. Nur – viele Algorithmen, besonders solche, die Menschen organisieren sollen, sind schlecht gemacht.
Schlecht gemachte Algorithmen
Anfang November 2016 kündigte Admiral Insurances, der drittgrößte Kfz-Versicherer Großbritanniens, an, sie würden künftig die Facebook-Profile ihrer KundInnen auswerten, um die Höhe der Versicherungsprämien für Führerscheinneulinge zu bestimmen, zu deren Fahrverhalten noch keine Daten vorliegen. Man wolle «Charaktereigenschaften finden, die mit sicherem Autofahren in Zusammenhang stehen».[1] Als positiv wurden Genauigkeit und Pünktlichkeit gewertet; diese wollte man daran festmachen, ob sich jemand mit seinen Freunden zu einer exakten Uhrzeit verabredet oder die Zeitangabe relativ offen hält («heute Abend»). Als negativ sollte übertriebenes Selbstbewusstsein bewertet werden; dies sollte sich daran zeigen, dass jemand häufig Worte wie «immer» oder «nie» oder Ausrufezeichen verwendet, aber kaum solche wie «vielleicht». Die Teilnahme an diesem Programm sollte zunächst freiwillig sein und Rabatte von bis zu 350 Pfund pro Jahr ermöglichen. Für viele junge AutofahrerInnen ist die «Freiwilligkeit» nur in einem sehr formalen Sinne gegeben: Sie können es sich nicht leisten, nicht mit ihren Daten zu bezahlen.
Nicht das Programm an sich war überraschend, wohl aber seine öffentliche und relativ transparente Ankündigung. Der Aufschrei war jedenfalls groß, und es dauerte keine 24 Stunden, bis Facebook erklärte, es werde diese Verwendung von Nutzerdaten nicht erlauben, sodass das Programm wiederzurückgezogen werden musste. Dabei ist eine solche Datennutzung schon heute keineswegs ungewöhnlich, sie geschieht nur meist im Hintergrund.[2] Das Interessante an diesem Fall ist, dass er exemplarisch aufzeigt, wie fragwürdig viele dieser automatischen Bewertungen und Handlungssysteme in der Praxis gemacht sind, ohne dass sie deshalb ihre Wirkmächtigkeit verlieren. Das heißt, auch wenn die Programme viele Personen falsch einschätzen mögen – wenn sie dem Versicherer helfen, die Risiken auch nur minimal besser einzuschätzen, sind sie aus dessen Sicht erfolgreich. Ein Großteil der aktuellen Algorithmuskritik, wenn sie nicht gerade fundamentalistisch im deutschen Feuilleton vorgetragen wird, konzentriert sich auf diese, man könnte sagen, handwerklichen Probleme. Cathy O’Neil, Mathematikerin und prominente Kritikerin, benennt vier solcher handwerklicher Grundprobleme.[3]
Überbewertung von Zahlen
Mit Big Data und den dazugehörigen Algorithmen erleben wir eine verstärkte Rückkehr der Mathematik und naturwissenschaftlicher Methoden in die Organisation des Sozialen. Damit einher geht eine Fokussierung auf Zahlen, die als objektiv, eindeutig und interpretationsfrei angesehen werden. Eins ist immer kleiner als Zwei. Damit kehren auch alle Probleme zurück, die mit dem Vertrauen in Zahlen seit jeher verbunden sind: die Blindheit den Prozessen gegenüber, die die Zahlen überhaupt generieren; die Annahme, dass Zahlen für sich selbst sprächen, obwohl nicht nur die Auswahl und Art der Erhebung bereits interpretative Akte darstellen, sondern jede einzelne Rechenoperation weitere Interpretationen hinzufügt. Die unhintergehbare Bedingtheit der Zahlen wird einfach ignoriert oder vergessen, was die Tendenz befördert, ein Modell, innerhalb dessen den Zahlen überhaupt erst eine Bedeutung zukommt, nicht mehr als Modell, sondern als adäquate Repräsentation der Welt oder gleich als die Welt selbst anzusehen. Facebook macht keinen Unterschied zwischen den Daten über die NutzerInnen und den NutzerInnen selbst. Postet jemand eine Nachricht, die als «fröhlich» klassifiziert wird, dann wird das als hinreichend angesehen, um zu behaupten, die Person sei wirklich gut gelaunt. Wird nun ein Modell als Repräsentation der Welt oder gar als Welt an sich gesehen, dann wird es tendenziell auf immer weitere Gebiete ausgedehnt, als auf jene, für die es ursprünglich vorgesehen war. Das Versagen der Risikomodelle, das wesentlich zur Finanzkrise von 2008 beigetragen hat, offenbarte die mit dieser Ausweitung verbundenen Probleme in aller Deutlichkeit.
Falsche Proxies
Das Problem der Überbewertung von Zahlen wird dadurch verschärft, dass gerade soziale Prozesse sich nicht einfach in Zahlen ausdrücken lassen. Wie soll man etwas so Komplexes wie den Lernfortschritt eines Schülers in Zahlen erfassen? Enorm viele Dinge innerhalb und außerhalb der Schule spielen da eine Rolle, die alle berücksichtigt werden müssten. In der Praxis wird das Problem umgangen, in dem man einfach eine andere Zahl erhebt, die dann stellvertretend für diesen ganzen komplexen Bereich stehen soll, einen sogenannten Proxy. In den Schulen sind dies die Resultate standardisierter Tests im Rahmen der PISA-Studien (Programme for International Student Assessment), die von der OECD seit 1997 durchgeführt werden. Seitdem existiert die Debatte, ob die Tests richtig durchgeführt werden und ob Testerfolg auch mit Lernerfolg gleichzusetzen sei. Das ist immerhin eine Debatte, die geführt werden kann. Richtig dramatisch wird die Sache hingegen, wenn solche im besten Fall umstrittenen Zahlen auf Dimensionen heruntergebrochen werden, wo sie auch innerhalb der statistischen Logik keine Aussagekraft mehr haben, etwa auf einzelne Schulen mit wenigen Hundert SchülerInnen oder gar auf Klassen mit weniger als 30 SchülerInnen, wenn es beispielsweise um die Bewertung der «Performance» einzelner LehrerInnen geht.
Auch wenn die gewonnenen Erkenntnisse oftmals kaum Aussagekraft enthalten, werden sie trotzdem für Bewertungen herangezogen, die bis zum Verlust der Arbeitsstelle führen können. Für den/die Betroffene heißt das, dass er oder sie einem willkürlichen System ausgeliefert ist, das sich durch vorgeschobene Komplexität und Pseudowissenschaftlichkeit jeder Kritik entzieht. Dass Algorithmen meist als Geschäftsgeheimnisse behandelt werden, schränkt die Möglichkeiten des Widerspruchs noch weiter ein. Um diesem Missverhältnis zu begegnen, müssen die Rechte der ArbeitnehmerInnen und der KonsumentInnen gestärkt werden, bis hin zu einem Recht auf Schadensersatz, wenn die Sorgfaltspflicht bei der Entscheidungsfindung durch Algorithmen verletzt wurde.
Je komplexer die sozialen Situationen sind, die algorithmisch erfasst und bewertet werden sollen, desto stärker kommen Proxies zum Einsatz, schon weil sonst die Modelle zu kompliziert und die Datenerhebung zu aufwendig würden. Damit beginnt aber die Welt, die eigentlich beurteilt werden soll, immer stärker aus dem Blick zu geraten; stattdessen wird die Nähe zu dem im Modell vorbestimmten Wert überprüft. Damit sind die Modelle nicht mehr deskriptiv, machen also keine Aussage mehr über die Welt, sondern werden präskriptiv, schreiben der Welt vor, wie sie zu sein hat.
Menschen passen ihr Verhalten an
Das Wissen um die Wirkmächtigkeit der quantitativen Modelle hat zur Folge, dass Menschen ihr Verhalten den Erwartungen des Modells anpassen und sich darauf konzentrieren, die richtigen Zahlen abzuliefern. Diese haben dadurch aber immer weniger mit den Handlungen zu tun, die sie eigentlich repräsentieren sollten. Alle, die schon einmal eine Tabelle so ausgefüllt haben, dass am Ende der angestrebte Wert geniert wurde, auch wenn das nicht den realen Prozessen entsprach, kennen diese Situation. Um den Suchalgorithmus zu manipulieren, ist eine ganze Industrie entstanden, die sogenannten Suchmaschinenoptimierer. Sie haben sich darauf spezialisiert, die innere Logik des Algorithmus zu erahnen und entsprechend die Inhalte ihrer KundInnen dieser Logik anzupassen, vollkommen unabhängig davon, ob das eine inhaltliche Verbesserung für die NutzerInnen darstellt oder nicht. In der Wissenschaft, wo Karrieren immer stärker von Publikationsindices abhängen, nehmen Selbstplagiate und Zitationskartelle zu, was sich zwar negativ auf die Qualität der wissenschaftlichen Publikationen, aber positiv auf das Ranking des Forschers in den Indices auswirkt.
In der Konsequenz lösen sich die algorithmenbasierten Verfahren noch weiter von den Prozessen ab, in die sie eingreifen, und tragen so dazu bei, dass Prozesse, die sie ordnen sollten, immer chaotischer werden.
Fehlende Transparenz und Korrigierbarkeit
Eine der häufigsten Reaktionen darauf, dass Menschen ihr Verhalten den quantifizierten Beurteilungsmustern anpassen, ist, dass diese Muster geheim gehalten werden: Die Menschen werden also im Unklaren darüber gelassen, ob und wie sie beurteilt werden, damit sich die «Ehrlichkeit» ihres Verhaltens erhöht und die numerische Klassifikation ihre Aussagekraft behält. Damit wird aber das Gefälle zwischen der durch Algorithmen erweiterten institutionellen Handlungsfähigkeit und dem Einzelnen, der dadurch organisiert werden soll, nur noch größer. Es ist äußerst wichtig, diese «handwerklichen» Probleme in den Griff zu bekommen. Appelle an die Ethik der EntwicklerInnen[4] oder die Selbstregulierung der Industrie werden hier nicht reichen.
Wir brauchen eine Anpassung der Gesetze, etwa jener, die gegen Diskriminierung schützen. Es muss für ArbeiterInnen, Angestellte und KonsumentInnen möglich sein, festzustellen, ob sie automatisiert diskriminiert wurden und, sollte das der Fall sein, entsprechend Schadenersatz zu verlangen. Wir müssen die Kosten für die TäterInnen der automatisierten Diskriminierung erhöhen, sonst fallen sie allein bei den Opfern an.
Es gibt keine autonome Technologie
Eine allein handwerklich argumentierende Kritik wäre aber nur eine sehr eingeschränkte Kritik. Es reicht nicht, die Qualität der Werkzeuge zu verbessern, denn Werkzeuge sind nie neutral, sondern reflektieren die Werthaltungen ihrer EntwicklerInnen und AnwenderInnen beziehungsweise deren Auftraggeber oder Forschungsförderer. Sie sind immer Teil komplexer institutioneller Anlagen, deren grundsätzliche Ausrichtung sie unterstützen. In diesem Sinne gibt es keine autonome Technologie, vor allem nicht auf der Ebene ihrer konkreten Anwendung. Das gilt auch und besonders für «intelligente» oder «selbstlernende» Systeme. Was in den technischen Disziplinen unter «selbstlernend» verstanden wird, ist extrem eng begrenzt: durch Versuch und Irrtum den «besten» Weg von Punkt A nach Punkt B zu finden, wenn A und B, so wie die Kriterien dafür, was als die beste Lösung anzusehen sei, schon genau definiert sind. Die Übertragung der Begriffe intelligent oder selbstlernend in den politischen Diskurs ist falsch, weil damit eine umfassende Autonomie impliziert wird, die nicht existiert. Das geschieht teilweise aus Technikeuphorie, teilweise als strategisches Manöver, um das eigentliche politische Programm, nämlich die Setzung der Punkte A und B, der Kritik zu entziehen.
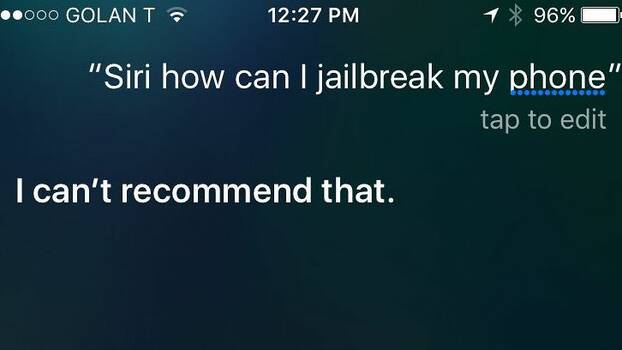
Ein Beispiel. Wenn man Siri, den smarten Assistenten von Apple, fragt: «Siri, how can I jailbreak my phone?» – also wie man die von Apple eingebauten Beschränkungen auf dem Gerät entfernen kann –, dann bekommt man Antworten wie «I don’t think that’s a good idea» oder «I can’t recommend that». Dies kann man als Rat oder Drohung auffassen. Jedenfalls ist deutlich, dass, egal wie smart Siri auch sein mag, er immer und vor allem der Assistent Apples sein wird, einfach deshalb, weil Apple die Punkte A und B definiert hat, zwischen denen sich Siri bewegen kann.
Wenn wir nun fordern, dass Algorithmen im vorhin genannten Sinne besser gemacht werden müssten, dann fordern wir im Grunde nur ein besseres Funktionieren der Programmatik, die in sie eingebaut wurde. Aber diese Programmatik ist keine harmlose Effizienz, sondern die Definition der Probleme und der möglichen Lösungen, und sie entspricht fast immer einer neoliberalen Weltsicht. Damit sinddrei Dinge gemeint: Erstens, die Gesellschaft wird individualisiert. Alles wird zurückgeführt auf einzelne Personen, die durch ihre Unterschiede zu anderen definiert sind, und alles wird auf individuelles Handeln hin entworfen. Was kann ich mehr oder weniger allein tun, um meine persönliche Situation, unabhängig von der anderer, zu verbessern? Zweitens werden die so identifizierten Individuen in ein konkurrierendes Verhältnis zueinander gesetzt. Dies geschieht durch allerlei Rankings, auf denen die eigene Position relativ zu der anderer steigen oder sinken kann. Drittens wird die Gruppe beziehungsweise das Kollektiv, welche das aufeinander bezogene Bewusstsein seiner Mitglieder zum Ausdruck bringt, ersetzt durch das Aggregat, das im Wesentlichen ohne Wissen der AkteurInnen gebildet wird. Entweder weil die angestrebte Ordnung spontan hervortreten soll, wie das Friedrich von Hayek für den Markt und die Gesellschaft annahm, oder weil sie hinter dem Rücken der Menschen in der Abgeschlossenheit der Rechenzentren konstruiert wird, sichtbar nur für einige wenige AkteurInnen.
Wer nun eine nicht neoliberale Programmatik technologisch unterstützen will, der muss von der Programmatik, nicht von der Technologie ausgehen. Ein wesentliches, durch die algorithmischen Systeme verstärktes Element der neoliberalen Programmatik ist es, wie erwähnt, individuelles Handeln zu privilegieren und Konkurrenz als zentralen Faktor der Motivation zu betonen. Eine alternative Programmatik müsste dagegen darauf ausgerichtet sein, neue Felder der Kooperation und des kollektiven Handelns zu erschließen.
Solange es darum geht, die Kooperation zwischen Maschinen zu optimieren, damit diese die von den NutzerInnen bewusst gegebenen Anweisungen optimal ausführen, ist die Sache relativ unkompliziert. Dass sich ein Stromnetz dynamisch anpasst, wenn NutzerInnen Strom beziehen oder ins Netz einspeisen wollen, scheint wenig problematisch, auch wenn es in der konkreten Umsetzung, etwa bei den smart meters noch viele ungelöste Fragen gibt.[5] Ähnlich verhält es sich mit einem selbst steuernden Auto, das sich den optimalen Weg zu dem angegebenen Ziel sucht. Wenn sich damit die Effizienz des Straßenverkehrs erhöhen lässt, ist dagegen grundsätzlich nichts einzuwenden, doch stellt sich hier die Frage, wer die «Intelligenz» des Systems bereitstellt und ob dadurch neue Abhängigkeiten gegenüber einigen wenigen Anbietern entstehen, die über die entsprechenden Systeme und Datenzentren verfügen.
Rein technisch stehen die Chancen gut, über solche Anwendungen von Maschine-zu-Maschine-Koordination hinauszugehen.Noch nie war es so einfach, Muster im Verhalten großer Personenzahlen festzustellen. Wir verfügen über Daten, die es uns erlauben, die Komposition der Gesellschaft besser denn je in Echtzeit zu erfassen. Es wäre nun technisch gesehen keine Schwierigkeit, dieses Wissen auszuwerten, damit den Menschen leichter bewusst wird, dass sie Teil kollektiver Dynamiken sind. Das geschieht auch bereits.
So zeigt Google seit knapp einem Jahr «beliebte Zeiten» an, um anzugeben, wann ein Geschäft oder ein öffentlicher Ort besonders stark besucht wird – vor kurzem sogar in Echtzeit die Besuchsfrequenzen des Stadthallenbades in Wien. Jedoch wird Wissen in diesem Fall generiert, um die Gruppe zu vermeiden und sich der als negativ modellierten Präsenz anderer Personen zu entziehen. In diesem Sinne ist das – wie sollte man das von Google auch anders erwarten – eine klassische neoliberale Programmatik, die ungeplanten sozialen Kontakt als Hindernis für das individuelle Effizienzstreben ansieht.
Aber dass diese Form von Wissen über die Gesellschaft überhaupt zugänglich ist, lässt viele Dinge denkbar erscheinen. Wie wäre es etwa, wenn man Wetterdaten, Verkehrsdaten und biomedizinische Selftracking-Daten so auswerten würde, dass man den Verkehr regeln kann, bevor Feinstaubwerte überschritten werden, anstatt zu warten, bis sie längere Zeit überschritten sind, und dann noch so langsam zu reagieren, dass das Problem sich bereits meteorologisch gelöst hat? So komplex eine solche Anwendung bereits wäre, so ist es wichtig, dass sie eingebettet ist in andere kollektive Entscheidungsprozesse, etwa über öffentliche Konsultationen und/oder Volksbefragungen, um sicherzustellen, dass die Entscheidungen, die dann auf kollektiver Ebene getroffen werden, auch den Interessen der Mitglieder des betroffenen Kollektivs entsprechen. Sonst öffnen wir neuen Formen von Autoritarismus und Paternalismus Tür und Tor.
Viele weitere Anwendungen ließen sich ausmalen. Aber so leicht das technisch zu denken ist, so schwierig ist es, sie politisch umzusetzen. Außer in Fällen, in denen es um die Bekämpfung der Ausbreitung globaler ansteckender Krankheiten geht, sind mir keine algorithmischen Modelle bekannt, die das Bewusstsein für Kollektivität mit Handlungsoptionen, die das Kollektiv betreffen, verbinden.
Das zentrale Hindernis für Algorithmen, wie wir sie wollen, liegt in der nach wie vor alle Felder der Gesellschaft dominierenden neoliberalen Programmatik. Die ist aber, nach Brexit und Trump, schwer angeschlagen. Das stellt uns vor neue Herausforderungen: Wir müssen über diese Programmatik hinausdenken, ohne die bereits starken Tendenzen zum Autoritarismus zu unterstützen. Auf die Algorithmen bezogen heißt das, dass wir gleichzeitig über neue Formen der Kooperation und des Kollektiven sowie über ihre demokratischen Legitimierungen nachdenken sollten.
Felix Stalder ist Professor für Digitale Kultur und Theorien der Vernetzung in Zürich, Vorstandsmitglied des World Information Institute in Wien und langjähriger Moderator der internationalen Mailingliste «nettime». Er forscht u. a. zu Netzkultur, Urheberrecht, Commons, Privatsphäre, Kontrollgesellschaft und Subjektivität. Zuletzt erschienen: «Kultur der Digitalität» (2016); felix.openflows.com
Dieser Text beruht auf einem Vortrag den Felix Stalder am 3.12.2016 auf der Konferenz «Unboxing. Algorithmen, Daten und Demokratie» gehalten hat.
[1] Ruddick, Graham: Admiral to price car insurance based on Facebook posts, in: Guardian, 2.11.2016, unter: www.theguardian.com/technology/2016/nov/02/admiral-to-price-car-insurance-based-on-facebook-posts.
[2] Christl, Wolfie: Kommerzielle digitale Überwachung im Alltag. Studie im Auftrag der Bundesarbeitskammer Wien, November 2014, unter: www.arbeiterkammer.at.
[3] O’Neil, Cathy: On Being a Data Sceptic, Sebastopol 2014; O’Neil, Cathy: Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy, London 2016.
[4] Vgl. The IEEE Global Initiative for Ethical Considerations in Artificial Intelligence and Autonomous Systems: Ethically Aligned Design. A Vision for Prioritizing Human Wellbeing with Artificial Intelligence and Autonomous Systems, Dezember 2016, unter: http://standards.ieee.org
[5] Das sind Fragen nach dem Datenschutz, aber auch nach der effektiven Effizienzsteigerung der Energienutzung, die zwar angestrebt und behauptet wird, sich aber bisher kaum nachweisen lässt. Eine vom Bundeswirtschaftsministerium in Auftrag gegebene Studie kam sogar zu einem negativen Kosten-Nutzen-Verhältnis für die EndkundInnen; vgl. Ernst & Young: Kosten-Nutzen-Analyse für einen flächendeckenden Einsatz intelligenter Zähler, Juni 2013, unter: www.bmwi.de.